爬取网易云音乐歌单里面的歌曲 | 臭大佬
爬取网易云音乐歌单里面的歌曲
数据表
CREATE TABLE `song_list` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '歌单名',
`link` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '链接',
`cover` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '略缩图',
`favorite` int(11) NOT NULL DEFAULT '0' COMMENT '收藏数',
`share` int(255) NOT NULL DEFAULT '0' COMMENT '分享数',
`author` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '作者',
`comment` int(11) NOT NULL DEFAULT '0' COMMENT '评论数',
`play_num` int(11) NOT NULL DEFAULT '0' COMMENT '播放次数',
`song_num` int(11) DEFAULT '0' COMMENT '歌曲数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1324 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `song` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cate_id` int(11) NOT NULL DEFAULT '0' COMMENT '所属分类',
`title` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '标题',
`link` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '链接',
`duration` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '时长',
`singer` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '歌手',
`album` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '专辑',
PRIMARY KEY (`id`),
KEY `cate_id` (`cate_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='歌曲表';
操作说明
我们在上一篇的基础上,给song_list表增加了多个字段,这样有利于统计数据,
如果song_list表没有数据的,需要先运行截图部分注释掉的代码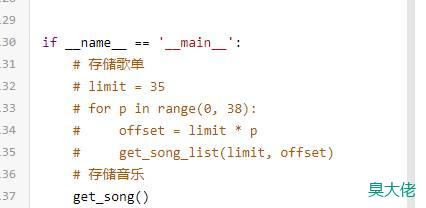
把本篇的代码改成如下,
if __name__ == '__main__':
# 存储歌单
limit = 35
for p in range(0, 38):
offset = limit * p
get_song_list(limit, offset)
# 存储音乐
#get_song()
运行完成后,再改回最终代码。
代码
# coding:utf-8
from bs4 import BeautifulSoup
import time
import pymysql
from selenium import webdriver
import re
# 引入 selenium 和实例化一个浏览器引擎
DRIVER = webdriver.Chrome(executable_path=r"./chromedriver.exe")
# 链接数据库
CON = pymysql.connect(host='localhost', port=3306, user='root', password='root', db='python_test',
charset='utf8mb4')
# 得到一个可以执行SQL语句的光标对象
CUR = CON.cursor()
BASEURL = 'https://music.163.com'
# 数据库操作
def db_write(sql):
print(sql)
try:
CUR.execute(sql)
CON.commit()
print("数据写入成功")
except Exception as e:
print(e)
# 获取歌单
def get_song_list(limit=35, offset=0):
reqUrl = BASEURL + '/#/discover/playlist/?order=hot&cat=全部&limit=' + str(limit) + '&offset=' + str(offset)
# 打开一个网页
DRIVER.get(reqUrl)
# 使用selenium切换frame
DRIVER.switch_to.frame("g_iframe")
req = DRIVER.page_source.encode('utf-8')
soup = BeautifulSoup(req, 'lxml')
songs = soup.select("p.dec > a")
for song in songs:
title = song.get('title')
link = BASEURL + song.get('href')
sql = "insert into song_list(title,link)values('{title}','{link}')".format(title=title, link=link)
db_write(sql)
# 获取歌曲
def get_song():
# 查询数据
CUR.execute('select link,id from song_list')
links = CUR.fetchall()
# 遍历
for link in links:
link_url = link[0]
link_id = link[1]
DRIVER.get(link_url)
# 等三秒,让页面加载完成
time.sleep(3)
# 使用selenium切换frame
DRIVER.switch_to.frame("g_iframe")
time.sleep(0.5)
cover = DRIVER.find_element_by_css_selector('.cover > img').get_attribute('src')
favorite = DRIVER.find_element_by_css_selector('.u-btni-fav > i').text
share = DRIVER.find_element_by_css_selector('.u-btni-share > i').text
# 正则去掉()
favorite = re.sub(r'[()]', '', favorite)
share = re.sub(r'[()]', '', share)
author = DRIVER.find_element_by_css_selector('.name > a').text
comment = DRIVER.find_element_by_css_selector('#cnt_comment_count').text
play_num = DRIVER.find_element_by_css_selector('#play-count').text
song_num = DRIVER.find_element_by_css_selector('#playlist-track-count').text
# 完善歌单表数据
song_list_sql = "UPDATE song_list SET cover='{cover}', favorite='{favorite}', share='{share}', author='{author}', comment='{comment}', play_num='{play_num}', song_num='{song_num}' where link='{link}'".format(
cover=cover, favorite=favorite, share=share, author=author, comment=comment, play_num=play_num,
song_num=song_num, link=link_url)
db_write(song_list_sql)
# 存储歌曲
songs_tr = DRIVER.find_elements_by_xpath('//table/tbody/tr')
for tr in songs_tr:
song_title = tr.find_element_by_css_selector(
"td:nth-child(2) > div > div > div > span > a > b").get_attribute('title')
song_link = tr.find_element_by_css_selector("td:nth-child(2) > div > div > div > span > a").get_attribute(
'href')
song_duration = tr.find_element_by_css_selector("td:nth-child(3) > span").text
song_singer = tr.find_element_by_css_selector("td:nth-child(4) > div").get_attribute('title')
song_album = tr.find_element_by_css_selector("td:nth-child(5) > div > a").get_attribute('title')
song_sql = "insert into song(cate_id,title,link,duration,singer,album)values('{cate_id}','{title}','{link}','{duration}','{singer}','{album}')".format(
cate_id=link_id, title=song_title, link=song_link, duration=song_duration, singer=song_singer,
album=song_album)
db_write(song_sql)
# 操作完成,关闭当前页
DRIVER.close()
if __name__ == '__main__':
# 存储歌单
# limit = 35
# for p in range(0, 38):
# offset = limit * p
# get_song_list(limit, offset)
# 存储音乐
get_song()
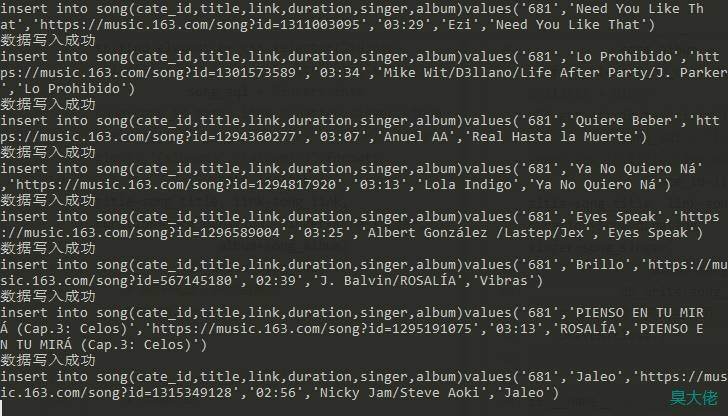
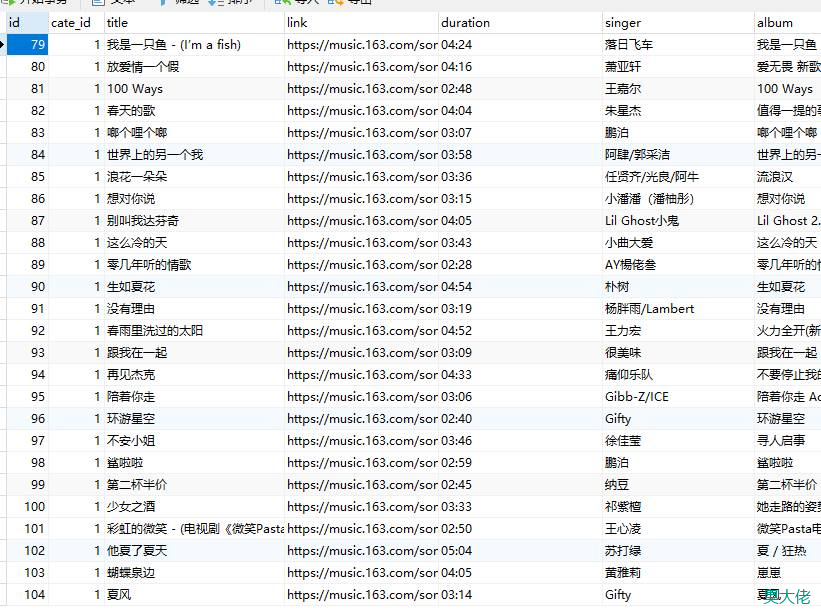
结果
本文链接:https://www.choudalao.com/article/134
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。