臭大佬解析Python多线程爬虫
多线程爬虫
测试
这里拿一个qj的cdn做测试,我们访问 20 次,获得 20 次文件,然后保存在本地。
普通爬虫
# coding:utf-8
import urllib.request
import time
# 文本下载函数
def downloadImage(url, filename):
print("从{}下载文本……".format(url))
urllib.request.urlretrieve(url, filename)
# 主函数
def main():
for i in range(20):
textName = "tmp/{}.jquery.min.js".format(i)
downloadImage("https://cdn.staticfile.org/jquery/1.10.2/jquery.min.js", textName)
if __name__ == '__main__':
t0 = time.time()
main()
t1 = time.time()
totaltime = t1 - t0
print("耗时:", totaltime)
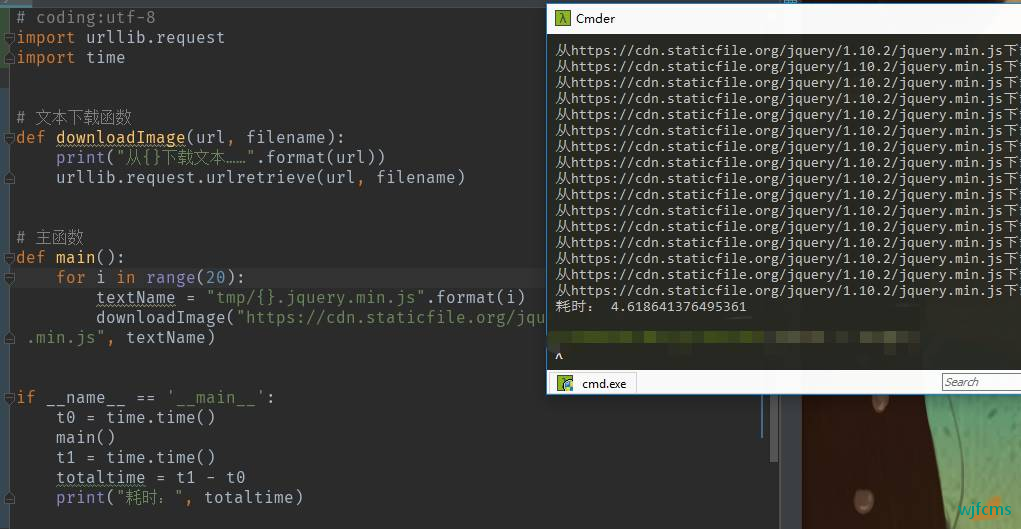
我们引入了模块 urllib.request,然后创建了一个函数downloadImage()用于下载文件,创建了一个函数 main()用于对下载函数进行遍历 20 次。耗时 4 秒多。
多线程
# coding:utf-8
import threading
import urllib.request
import time
def downloadImage(url, filename):
print("从{}下载文本……".format(url))
urllib.request.urlretrieve(url, filename)
print("完成下载")
def executeThread(i):
textName = "tmp/{}.jquery.min.js".format(i)
downloadImage("https://cdn.staticfile.org/jquery/1.10.2/jquery.min.js", textName)
def main():
threads = []
for i in range(20):
thread = threading.Thread(target=executeThread, args=(i,))
threads.append(thread)
thread.start()
for i in threads:
i.join()
if __name__ == '__main__':
t0 = time.time()
main()
t1 = time.time()
total = t1 - t0
print("消耗时间:{}".format(total))
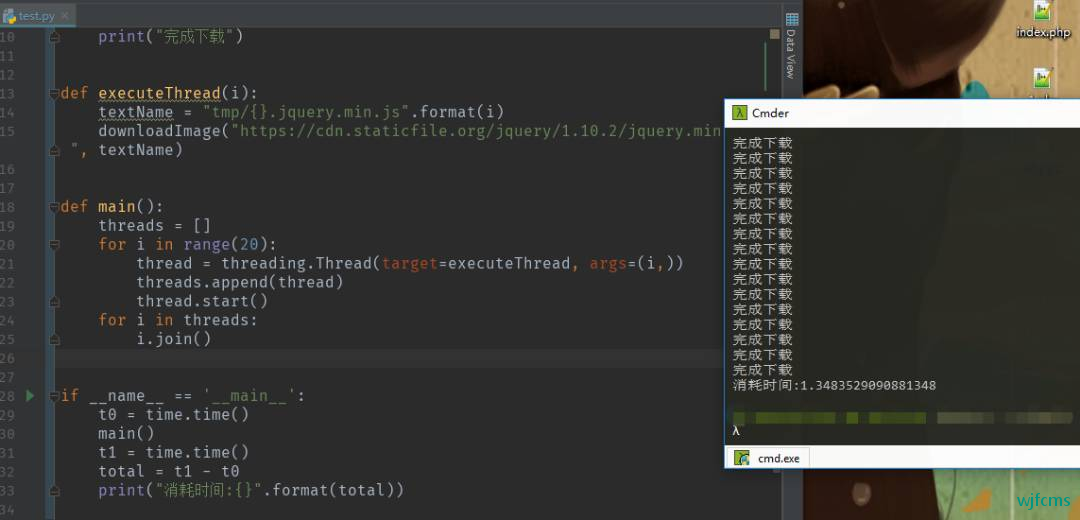
程序的前部分大同小异,后面我们创建了一个 threads 列表,,然后遍历 20 次,创建一个新的线程对象,将其添加到 threads 列表中,然后启动该线程。
最后,我们通过遍历我们的 threads 列表来调用我们的线程,然后调用 join()方法在每个线程上,这确保我们在下载完文件之前,不会执行剩下的代码。
运行代码,可以发现程序几乎同时启动了 20 个下载任务,然后在图片下载完成后,再打印出来。耗时 1 秒,效率提高很多
多线程爬取臭大佬文章
# coding:utf-8
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
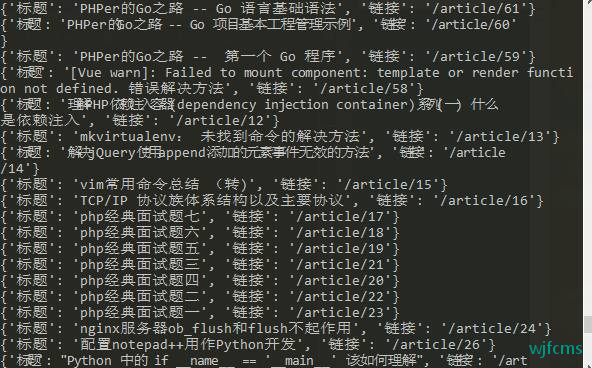
def get_news(page):
url = 'https://www.choudalao.com/?page='+str(page)
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata, 'lxml')
news_titles = soup.select("#body_app > article > div.blogs > ul > li > h3 > a")
if news_titles:
for n in news_titles:
# 提取出标题和连接信息
title = n.get_text()
link = n.get("href")
# 将提取出来的信息拼接为一个字典
data = {
'标题': title,
'链接': link
}
print(data)
if __name__ == '__main__':
pool = Pool()
# 假设我们只爬取9页
pool.map_async(get_news,range(1,9))
pool.close()
pool.join()
本文链接:https://www.choudalao.com/article/122
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。