臭大佬教你使用 Selenium 模拟浏览器操作
Selenium 是一个浏览器自动化测试框架,其能够调用相关的接口来运行浏览器并执行一系列的动作,就像是真正的用户在网页上操作一样。
前提
除了在网页中使用接口外,还有的网站会在页面中使用大量的 Javascript 函数进行页面的各种交互和数据生成。这样的网站或者数据,我们在浏览器控制的“Network”选项卡中是找不到相关的接口的。那么该怎么办呢?
我们可以使用一个 Web 的自动化测试工具——Selenium 来调用真实的浏览器内核来进行数据采集。
Selenium 是一个浏览器自动化测试框架,其能够调用相关的接口来运行浏览器并执行一系列的动作,就像是真正的用户在网页上操作一样。Selenium 最初多用于 Web 应用的功能测试中,后来因为其能够调用浏览器的特性,能够绕过很多的反爬虫机制,日益在爬虫领域流行开来。
一个完整的 selenium 由两部分组成:
- selenium 框架
- webdriver——浏览器驱动器
其中,selenium 负责接收程序的指令和操作,webdriver 负责具体的浏览器动作的执行。
安装 selenium
pip install selenium
下载安装 webdriver
在 selenium 中,我们通常有四种浏览器驱动方案:
- Chrome 浏览器
- FireFox 浏览器
- IE 浏览器
- PhantomJS 无头浏览器
前三种浏览器我们都很熟悉,PhantomJS 浏览器则很少接触。PhantomJS 浏览器是一个无头的
浏览器引擎,它没有实际的应用界面,可通过脚本来编程操作,相比较其他三种浏览器而已,内
存占用更小,更适合集成和部署。
三种浏览器引擎在 selenium 中的使用方法大同小异,在实际环境中我们推荐使用 PhantomJS,
但是为了方便演示,我们在此使用 Chrome 的引擎进行介绍。
查看谷歌版本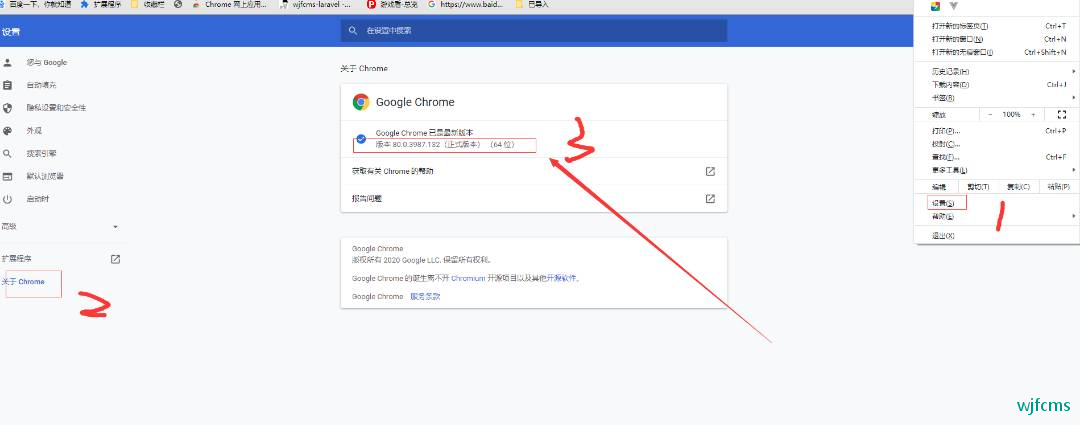
镜像地址:
http://npm.taobao.org/mirrors/chromedriver/
找到对应版本后下载对应版本的webdriver。
win下载这个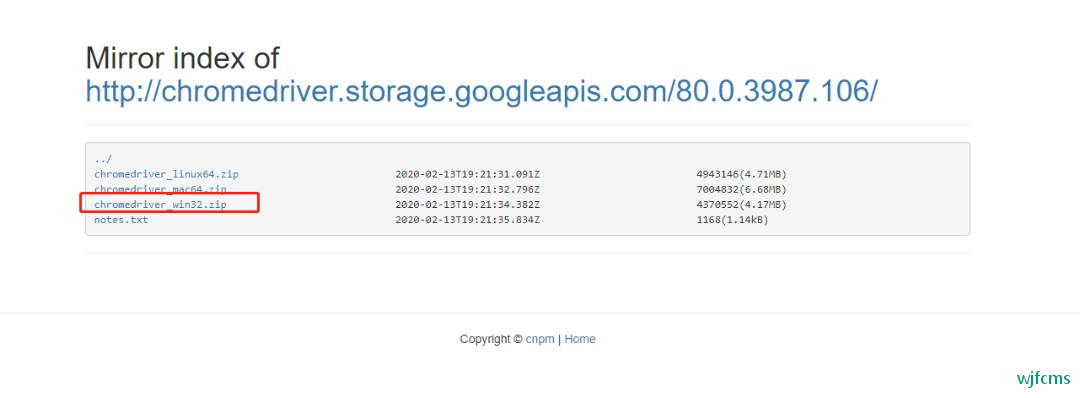
下载后,压缩包内windows系统下为exe文件,ubuntu下为elf文件,将压缩包内的可执行文件放在你自己知道的一个任意目录下。
这样我们的webdriver就已经下载完成了,在selenium中使用API指定相关路径,就可以进行自动化测试了。
引入 selenium 和实例化一个浏览器引擎
# coding:utf-8
from selenium import webdriver
# 引入 selenium 和实例化一个浏览器引擎
driver = webdriver.Chrome(executable_path=r"E:\wwwroot\python\PyTest\test\chromedriver.exe")
打开一个网页
driver.get('http://www.baidu.com')
元素定位
在 requestss+BeautifulSoup 的模式中,我们一般使用 css 选择器和 find()方法来进行元素的地位
和解析,而在 selenium 中,我们有七种方式对元素进行定位:
- 根据 ID 名进行定位——find_element_by_id()方法;
- 根据 name 名进行定位——find_element_by_name()方法;
- 根据 Class 类名进行定位——find_element_by_class_name()方法;
- 根据标签名进行定位——find_element_by_tag_name()方法;
- 根据 CSS 选择器进行定位——find_element_by_css_selector()方法;
- 根据链接文字进行定位——find_element_by_link_text()方法;
- 根据 xpath 进行定位——find_elements_by_xpath()方法(返回多个节点);
- 根据 xpath 进行定位——find_element_by_xpath()方法(返回单个节点);
获取元素值
在定位到元素之后,我们需要获取相应元素的文本值或者是属性值。在 selenium 中可以使用 text
属性获取元素的文本值,使用 get_attribute()方法获取元素的属性值。
保存页面代码供 BeautifulSoup
除了直接使用 selenium 定位元素的方法和获取值的方法外,我们可以将 selenium 打开后的网页
保存为源码,再将其传输给 BeautifulSoup 用于元素定位和文本解析。
selenium 中将网页保存为源码的方法为 page_source:
wbdata = driver.page_source
示例:
# coding:utf-8
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome(executable_path=r"E:\wwwroot\python\PyTest\test\chromedriver.exe")
driver.get('http://www.toutiao.com')
wbdata = driver.page_source
soup = BeautifulSoup(wbdata,'lxml')
img_news = soup.select('div.bui-box > div.bui-left > div.bui-box > ul.slide-list.bui-
left > li > a')
for i in img_news:
print(i.get_text())
表单输入与点击事件
一些网页,我们需要输入表单之后才能获取结果。在 selenium 中,我们可以先定位到表单元素,
然后使用 send_keys()方法,在表单中输入文本,然后使用 click()方法或者 submit()方法进行提
交。
- send_keys()——用于在输入框中输入文本;
- clear()——用于清空输入框中原有的文本;
- click()——点击一个按钮;
- submit()——提交一个表单;
下面我们以百度搜索为例,使用 selenium 输入关键词“臭大佬”并进行搜索:
# coding:utf-8
from selenium import webdriver
import time
# 引入 selenium 和实例化一个浏览器引擎
driver = webdriver.Chrome(executable_path=r"E:\wwwroot\python\PyTest\test\chromedriver.exe")
# 打开首页
driver.get('http://www.baidu.com')
# 定位搜索框
inputs = driver.find_element_by_id('kw')
# 在搜索框中输入文本
inputs.send_keys('臭大佬')
# 定位"百度一下"搜索按钮
search = driver.find_element_by_id('su')
# 点击搜索按钮
search.click()
# 等待 5 秒
time.sleep(5)
# 进行屏幕截屏
driver.save_screenshot('search_choudalao.jpg')
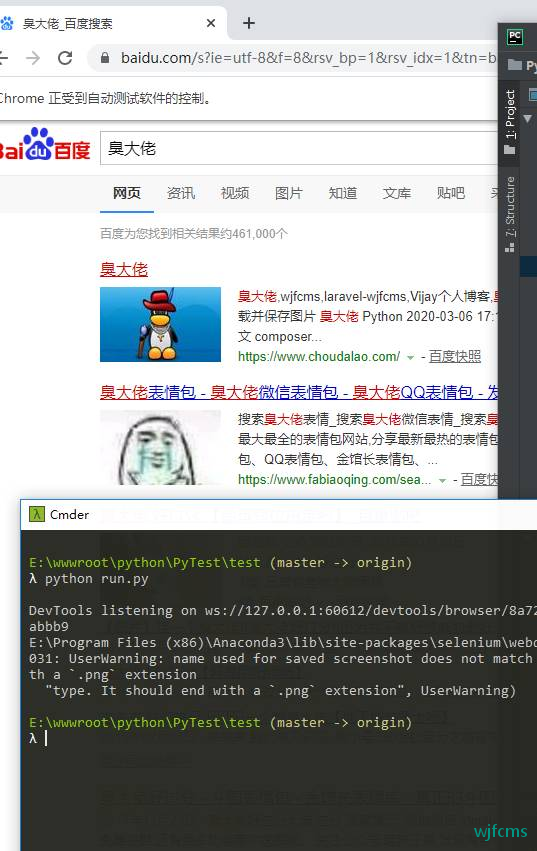

切换框架(iframe) 和窗口
在 html 中,iframe 标签用来创建一个包含在网页文档中的另一个文档框架,在 iframe 中可以自
定义 html 的页面、样式和内容。
默认情况下,Selenium 打开和操作的都是最外层的框架,如果我们需要提取的内容或是需要输入
的表单以及点击的按钮存在于子框架(iframe)中,我们就需要先切换定位在子框架上。
另一个情况就是,某些链接点击之后会新建一个窗口,新的内容出现在新的窗口上,这时候我们
也需要将窗口切换到新的窗口中。
在 selenium 中,我们可以使用 switch_to 来对框架和窗口进行切换:
- switch_to.frame(框架名):切换框架;
- switch_to.window(窗口名):切换窗口;
执行 js 代码
在某些特殊情况下,我们的点击按钮或是其他浏览器行为使用 selenium 的内置方法操作不了(比
如 PhantomJS 引擎不支持非 button 元素的点击事件),那么可以执行 JS 代码来对浏览器进行
操作。
在 selenium 中执行 js 代码的方法为:execute_script()
driver.execute_script(js 代码)
在linux中安装使用
contents中
如果是宝塔环境,默认是python2的,运行如下命令,安装独立版python3,这种情况下,后面的所有python和pip命令都要变成python3和pip3
curl https://download.bt.cn/install/update_panel.sh|bash
python3 -V

pip3 install selenium
下载谷歌浏览器
yum install https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
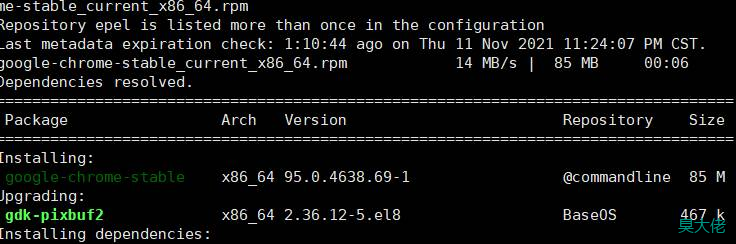
这个命令是下载安装最新的稳定的chrome版本,不是固定的版本,所以要注意下载chromedriver时要对应版本
我是在本地win10系统又下了一遍,由于winRAR无法解压,为此我还特意下载了个360解压,解压可以看到chrome版本是95.0.4638.69

安装依赖库
yum install pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXtst.x86_64 cups-libs.x86_64 libXScrnSaver.x86_64 libXrandr.x86_64 GConf2.x86_64 alsa-lib.x86_64 atk.x86_64 gtk3.x86_64 -y
安装chromedriver(驱动程序)
打开链接:http://chromedriver.storage.googleapis.com/index.html , 我刚才chrome版本是95.0.4638.69,找到自己对应的版本.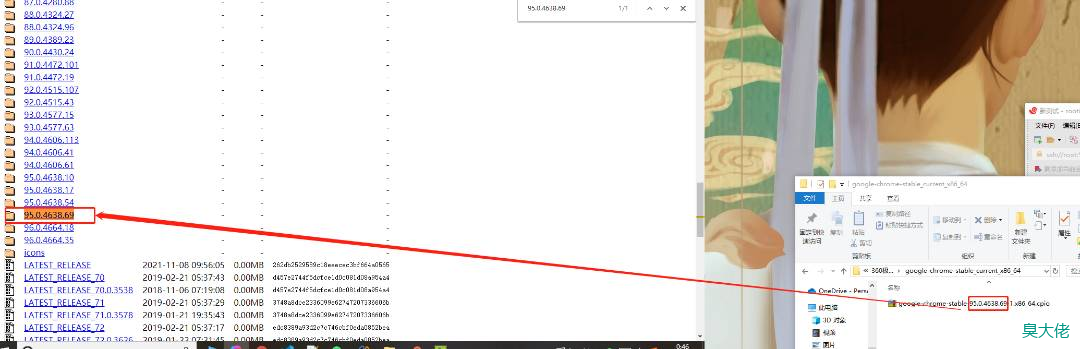
进入到目录中,下载linux版本,
wget http://chromedriver.storage.googleapis.com/95.0.4638.69/chromedriver_linux64.zip
解压
unzip chromedriver_linux64.zip

给予运行权限
chmod +x chromedriver
放到环境变量PATH路径中
cp chromedriver /usr/bin/
查看chromedriver的版本
chromedriver --version

测试
进行脚本测试(1.py)
#coding:utf-8
from selenium import webdriver
ch_options = webdriver.ChromeOptions()
# 为Chrome配置无头模式
ch_options.add_argument("--headless")
ch_options.add_argument('--no-sandbox')
ch_options.add_argument('--disable-gpu')
ch_options.add_argument('--disable-dev-shm-usage')
# 在启动浏览器时加入配置
dr = webdriver.Chrome(options=ch_options)
# 这是测试网站
url = "https://www.baidu.com"
dr.get(url)
# 打印源码
print(dr.page_source)
能打印页面说明就成功了
问题
DeprecationWarning: executable_path has been deprecated, please pass in a Service object
解决方式:https://blog.csdn.net/qq_57377057/article/details/128463296
AttributeError: ‘WebDriver’ object has no attribute ‘find_element_by_id’
由于版本迭代,新版的selenium已经不再使用find_element_by_id方法。
browser.find_element_by_id(‘su’)修改为如下语句,
browser.find_element(By.ID,’su’)
本文链接:https://www.choudalao.com/article/123
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。