Spider爬取臭大佬首页文章
Spider爬取臭大佬首页文章
创建Scrapy项目
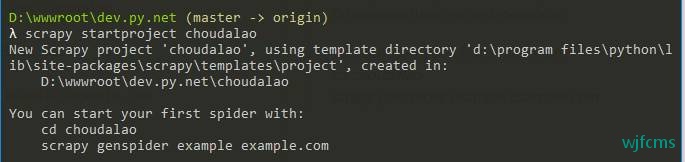
scrapy startproject choudalao
λ scrapy startproject choudalao
New Scrapy project ‘choudalao’, using template directory ‘d:\program files\python\lib\site-packages\scrapy\templates\project’, created in:
D:\wwwroot\dev.py.net\choudalaoYou can start your first spider with:
cd choudalao
scrapy genspider example example.com
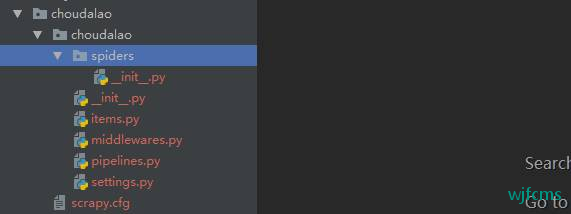
目录结构:
创建爬虫
进入spider目录下,运行命令
scrapy genspider choudalao "choudalao.com"

分析
打开臭大佬首页,分析数据结构: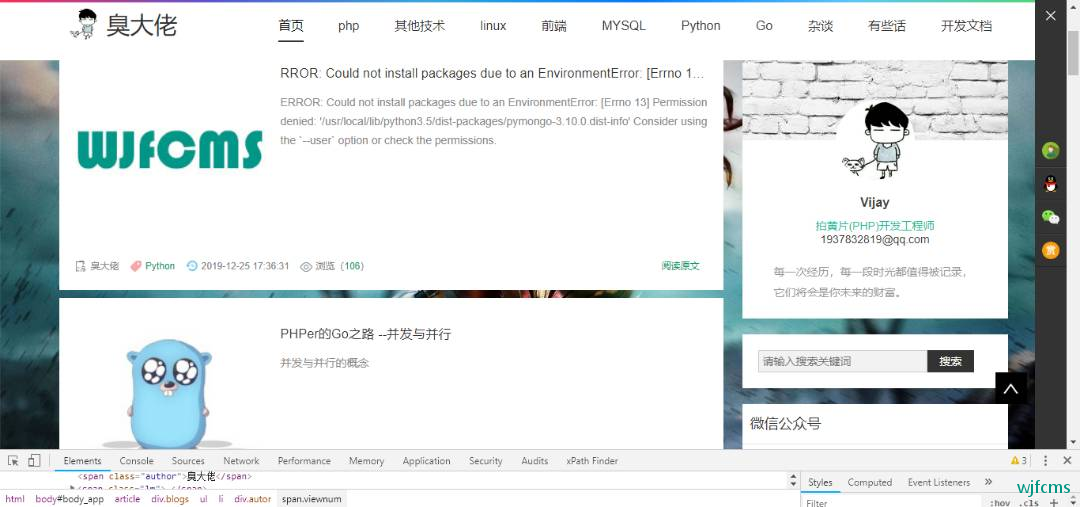
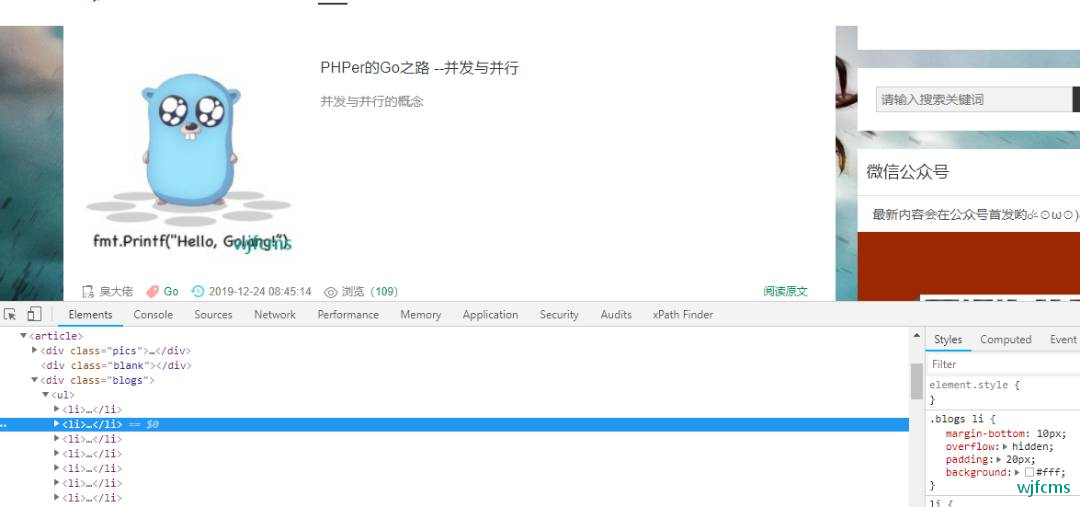
每一个li里面都包含标题、作者、链接、标签、浏览数、时间等等。我们就提取这几个字段。
利用xPath提取内容
//div[@class="blogs"]/ul/li
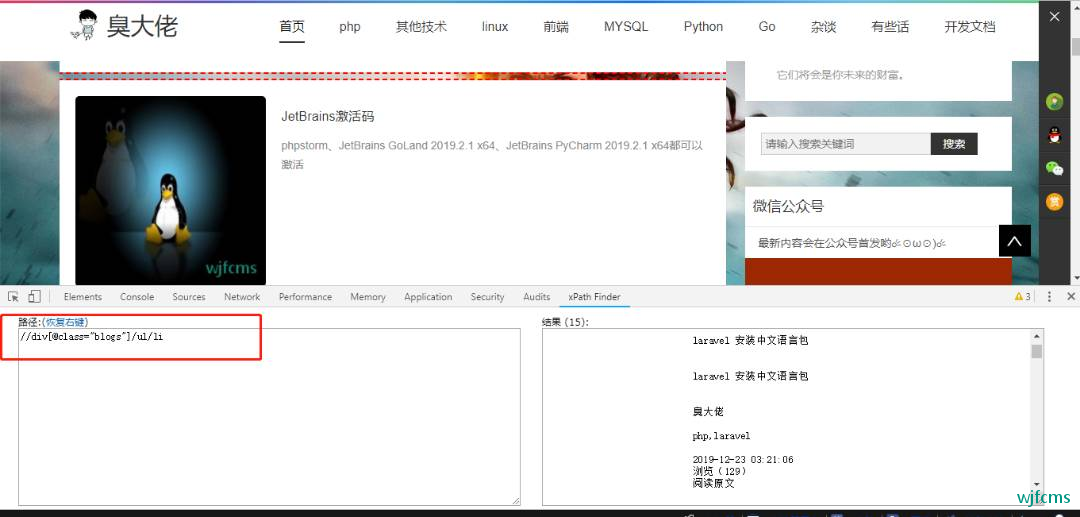
提取所有标题: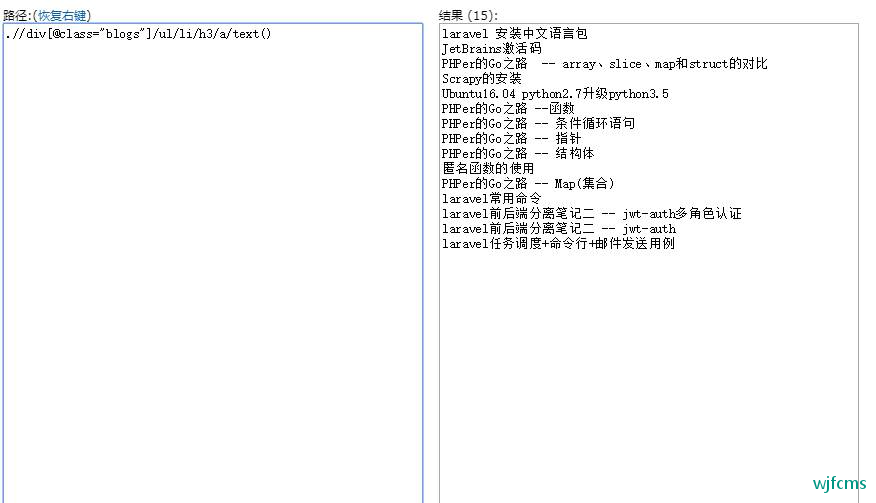
别的以此类推
设置字段
打开 items.py,编辑如下:
class ChoudalaoItem(scrapy.Item):
# 文章标题
title = scrapy.Field()
# 作者
author = scrapy.Field()
# 链接
link = scrapy.Field()
# 标签
keyword = scrapy.Field()
# 浏览数
looks = scrapy.Field()
# 时间
craete_time = scrapy.Field()
提取数据
# -*- coding: utf-8 -*-
import scrapy
from choudalao.items import ChoudalaoItem
class ChoudalaoSpider(scrapy.Spider):
name = 'choudalao'
allowed_domains = ['www.choudalao.com']
# 起始地址(带分页)
baseUrl = "https://www.choudalao.com/?page="
page = 1
start_urls = [baseUrl + str(page)]
def parse(self, response):
# 接收数据
node_list = response.xpath('//div[@class="blogs"]/ul/li')
# 遍历数据
for node in node_list:
# 存储到每个item
item = ChoudalaoItem()
# 标题
item['title'] = node.xpath('./h3/a/text()').extract()[0]
# 标签
item['keyword'] = node.xpath('./div[@class="autor"]/span[@class="lm"]/a/text()').extract()[0]
# 作者
item['author'] = node.xpath('./div[@class="autor"]/span[@class="author"]/text()').extract()[0]
# 链接
item['link'] = node.xpath('./span[@class="blogpic"]/a/@href').extract()[0]
# 浏览数
item['looks'] = node.xpath('./div[@class="autor"]/span[@class="viewnum"]/a/text()').extract()[0]
# 时间
item['craete_time'] = node.xpath('./div[@class="autor"]/span[@class="dtime"]/text()').extract()[0]
yield item
编写管道文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ChoudalaoPipeline(object):
def __init__(self):
self.f = open("choudalao.json", "w", encoding='utf-8')
def process_item(self, item, spider):
# 转成字典,写入json格式
content = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.f.write(content)
return item
def clone_spider(self, spider):
self.f.close()
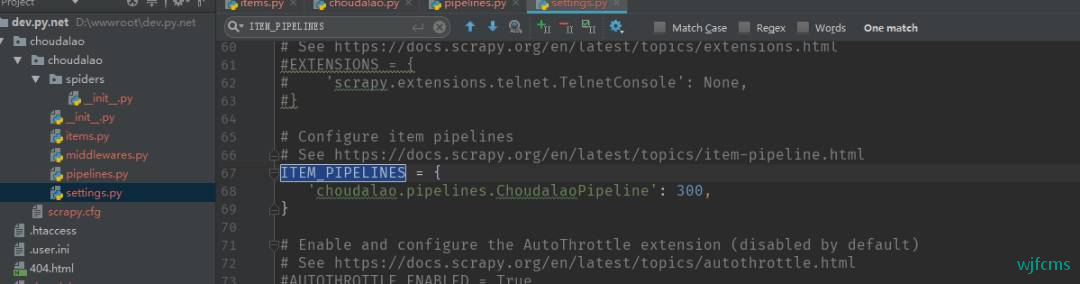
配置启用管道
在settings.py文件中搜索ITEM_PIPELINES,打开注释
ITEM_PIPELINES = {
'choudalao.pipelines.ChoudalaoPipeline': 300,
}
运行
scrapy crawl choudalao
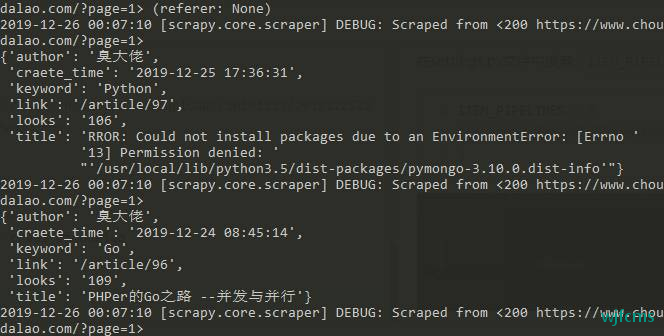
抓取的数据截图
本文链接:https://www.choudalao.com/article/98
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。