计算机是怎样跑起来的 之二
计算机是怎样跑起来的
第六章 与数据结构成为好朋友的七个要点
程序中的变量是指什么?
变量是数据的容器。变量中所存储的数据是可以改变的。变量的实质是按照变量所存储数据的大小被分配到的一块内存空间。
数组
数组实际上是为了存储多个数据而在内存上集中分配出的一块内存空间,并且为这块空间整体赋予了一个名字。
数组是指多个同样数据类型的数据在内存中连续排列的形式。作为数组元素的各个数据会通过连续的编号被区分开来,这个编号称为 索引(index)。
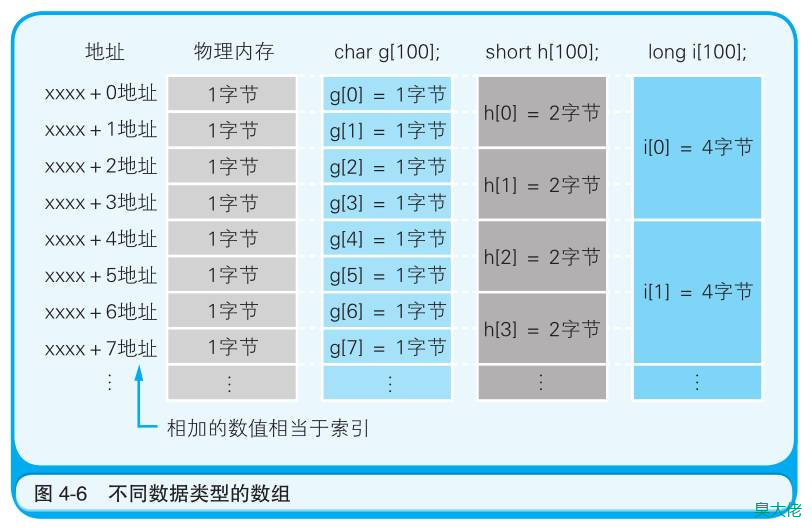
栈
数据的使用顺序与堆积顺序是相反的。通常把这种存取方式称为 LIFO(Last In First Out,后进先出),即最后被存入的数据是最先被处理的。
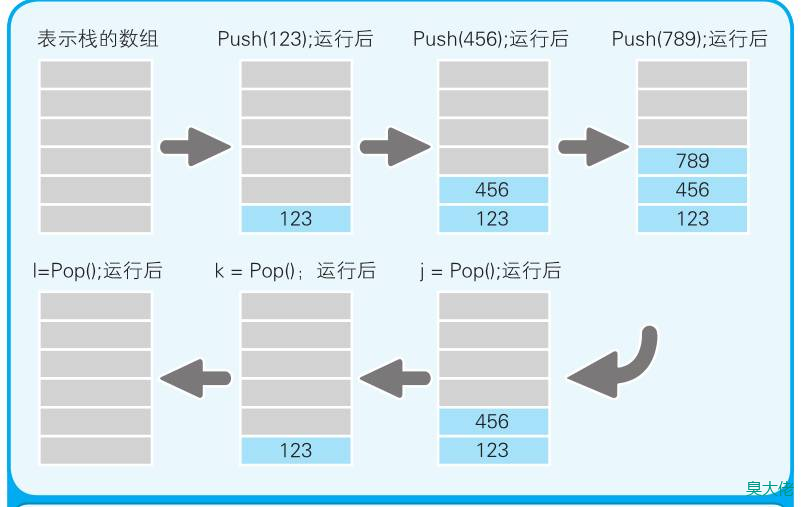
队列
通常把这种形式称为 FIFO(First In First Out,先进先出),即最先被存入的数据也是最先被处理的。当无法一下子处理完数据的时候,就可以暂且先把这些数据排成队。
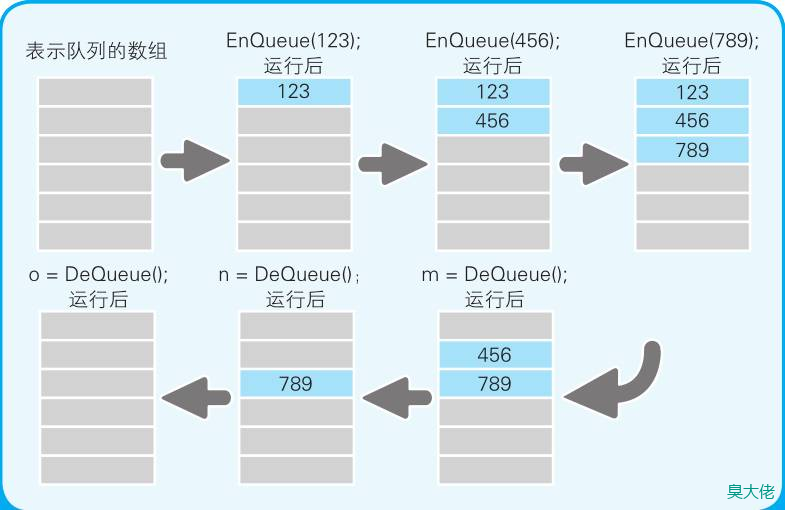
链表
是一种物理存储单元上非连续、非顺序的存储结构。数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
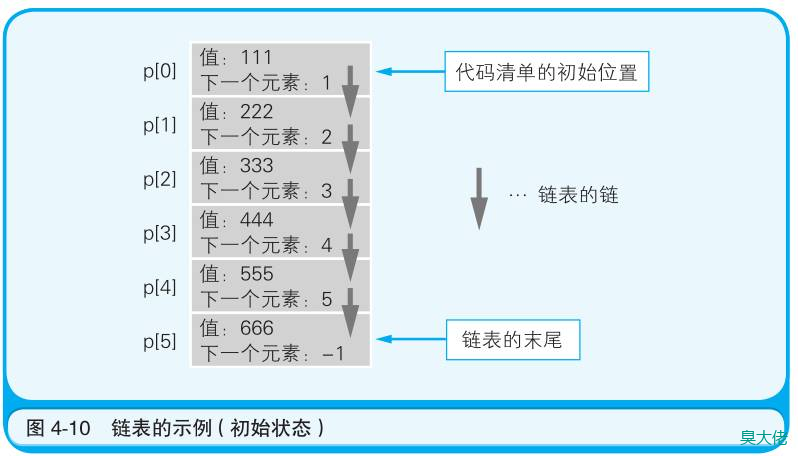
删除元素
只需要把元素索引信息变成后面元素的索引就可以实现删除(虽然物理内存中还是有残留的)
如删除p[3],只需要把p[2]的下一个索引变成4。
追加元素
修改当前元素的索引,并设置新元素的索引为当前元素之前的索引,
如在p[4]后增加一个p[8],p[4]的下一个元素改成8,p[8]下一个元素改成5.
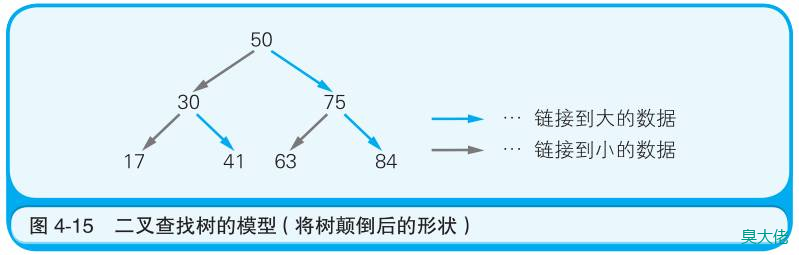
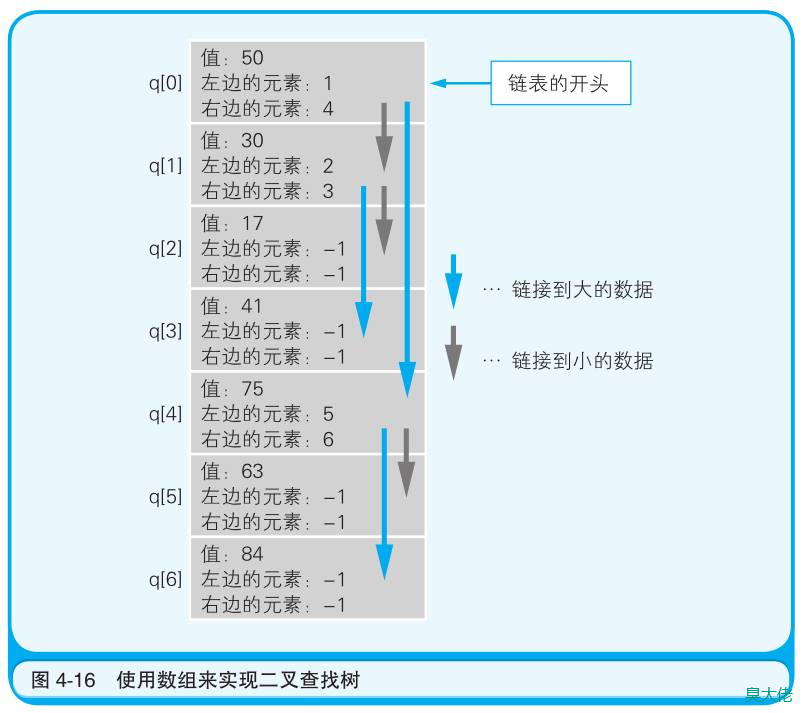
二叉树
在链表的基础上往数组中追加元素时,考虑到数据的大小关系,将其分成左右两个方向的表现形式。其实数组的每个元素中只要有数据的值和两个索引信息就可以了。
结构体
所谓结构体,就是把若干个数据项汇集到一处并赋予其名字后所形成的一个整体。
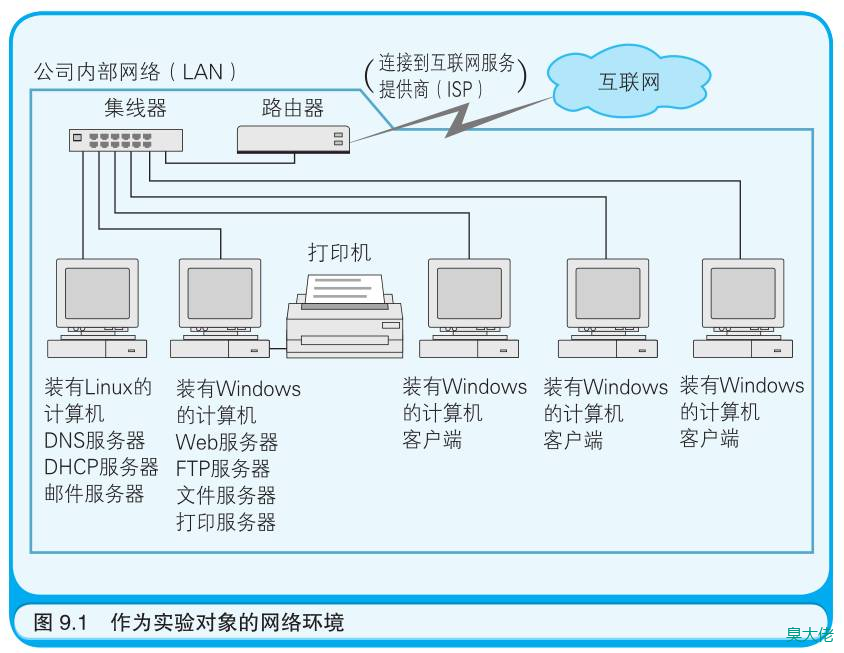
集线器
(Hub)是负责把各台计算机的网线相互连接在一起的集线设备。
路由器
(Router)是负责把局部网络和互联网连接起来的设备。
载波监听(Career Sense)
指的是这套机制会去监听(Sense)表示网络是否正在使用的电信号(Career)。
多路复用(Multiple Access)
指的是多个(Multiple)设备可以同时访问(Access)传输介质。
带冲突检测(with Collision Detection)
表示这套机制会去检测(Detection)因同一时刻的传输而导致的电信号冲突(Collision)。
在 TCP/IP 网络中,传输的数据都会携带 MAC 地址和 IP 地址两个地址。
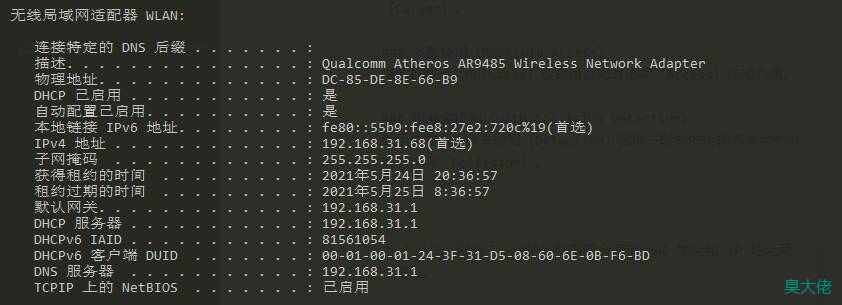
查看 IP 地址
ipconfig /all
*注:
子网掩码的作用是标识出在 32 比特的 IP 地址中,从哪一位到哪一位是网络地址,从哪一位到哪一位是主机地址。
把 255.255.255.0 用二进制表示的话,结果如下:
11111111.11111111.11111111.00000000
子网掩码中,值为 1 的那些位对应着 IP 地址中的网络地址,后面
注:
子网掩码的作用是标识出在 32 比特的 IP 地址中,从哪一位到哪一位是网络地址,从哪一位到哪一位是主机地址。
把 255.255.255.0 用二进制表示的话,结果如下:> 11111111.11111111.11111111.00000000子网掩码中,值为 1 的那些位对应着 IP 地址中的网络地址,后面
值为 0 的那些位则对应着主机地址。因此 255.255.255.0 这个子网掩码就表示,其所对应的 IP 地址前 24 比特是网络地址,后 8 比特是主机地址。8 个二进制数可以表示的范围是从 00000000 到 11111111,共 255 个数。而因为最开始的 00000000 和最后的 11111111 具有特殊的用途,所以最多可以配置 253 台计算机,它们的主机地址范围是从 00000001 到 11111110。但是这其中又有一台路由器,所以实际上最多只能放置 252 台计算机。与 MAC 地址一样,每个 IP 地址的值也都是独一无二的。
DHCP 的全称是 Dynamic Host Configuration Protocol(动态主机设置协议)。DHCP 服务器上记录着可以被分配到 LAN 内计算机的 IP 地址范围和子网掩码的值。
路由器的作用
路由器正如其名,就是决定数据传输路径的设备。与 LAN 内的其他计算机一样,路由器也是连接在集线器上的。因为 LAN 内采用了 CSMA/CD 机制,所以所有发送出去的数据也都会发到路由器上。当从公司内的计算机向另一家公司的计算机发送数据时会发生什么呢?首先,一个不属于 LAN 内计算机的 IP 地址会被附加到数据的发送目的地字段上。这样的数据虽然会被 LAN 内的计算机所忽略,但是不会被路由器忽略。因为路由器的工作原理就是查看附加到数据上的 IP 地址中的网络地址部分,只要发现这个数据不是发送给 LAN 内计算机的,就把它发送到 LAN 外,即互联网的世界中。
路由器虽然看起来就是个小盒子,可实际上是一台神奇的计算机。分布在世界各地的 LAN 中的路由器相互交换着信息,互联网正是由于这种信息的交换才得以联通。这种信息被称作“路由表”,用来记录应该把数据转发到哪里。在像互联网这样的网络中,传输路径错综复杂,而路由器就是站在各个岔路口的指路人。在一台路由器的路由表中,只会记录通往与之相邻的路由器的路径,而并不会记录世界范围内的所有传输路径。
查看路由表
route print
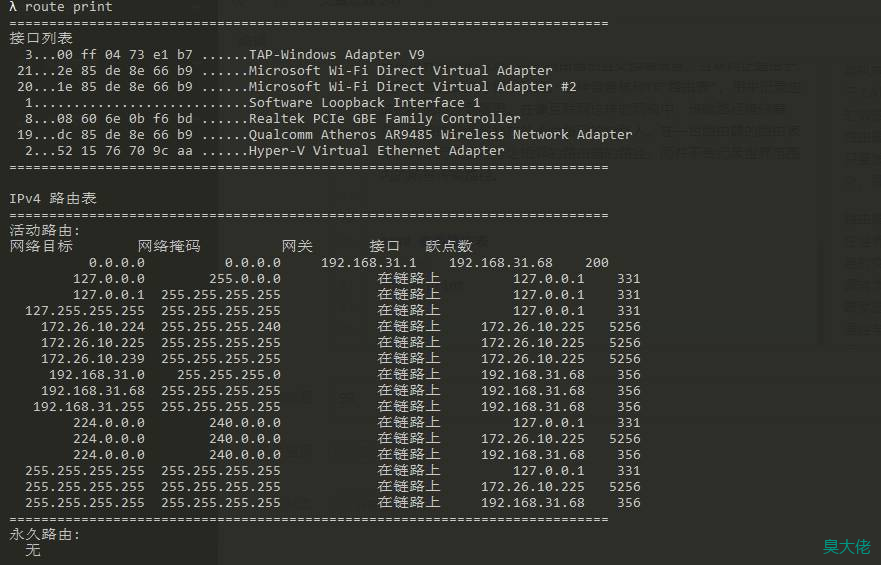
如果遇到有多条候选路径都可以通往目的地的情况,路由器就会选择 跃点数(Metric) 值较小的那条路径。在路由表中还有如下的规则:如果数据的发送目的地就在本 LAN 中,则可以直接发送数据而无需经过路由器转发;反之如果在 LAN 外(或发送目的地的 IP 地址不在路由表中),则需要经过路由器转发。细节虽然有些复杂,但是只要了解了大体上的规则就可以了。
查看路由器的路由过程
tracert工作原理
Tracert 命令用 IP 生存时间 (TTL) 字段和 ICMP 错误消息来确定从一个主机到网络上其他主机的路由。
首先,tracert送出一个TTL是1的IP 数据包到目的地,当路径上的第一个路由器收到这个数据包时,它将TTL减1。此时,TTL变为0,所以该路由器会将此数据包丢掉,并送回一个「ICMP time exceeded」消息(包括发IP包的源地址,IP包的所有内容及路由器的IP地址),tracert 收到这个消息后,便知道这个路由器存在于这个路径上,接着tracert 再送出另一个TTL是2 的数据包,发现第2个路由器…… tracert 每次将送出的数据包的TTL 加1来发现另一个路由器,这个重复的动作一直持续到某个数据包 抵达目的地。当数据包到达目的地后,该主机则不会送回ICMP time exceeded消息,一旦到达目的地,由于tracert通过UDP数据包向不常见端口(30000以上)发送数据包,因此会收到「ICMP port unreachable」消息,故可判断到达目的地。
tracert 有一个固定的时间等待响应(ICMP TTL到期消息)。如果这个时间过了,它将打印出一系列的*号表明:在这个路径上,这个设备不能在给定的时间内发出ICMP TTL到期消息的响应。然后,Tracert给TTL记数器加1,继续进行。(注意:默认是最多30跳就结束 。
tracert www.choudalao.com
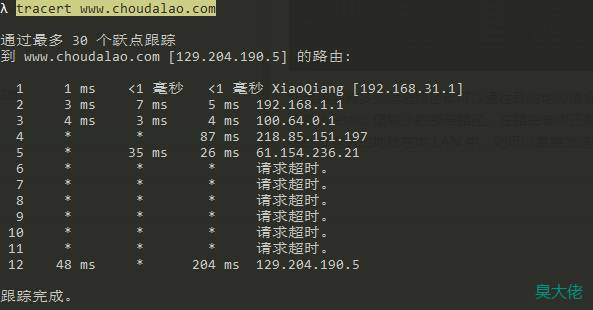
一般情况下,第一行是lan内的路由器,之后是其他服务提供商的路由器,最后一行是目标的we服务器。
DNS 服务器
DNS(Domain Name System,域名系统)服务器:可以把主机名解析成 IP 地址
nslookup作用
nslookup用于查询DNS的记录,查询域名解析是否正常,在网络故障时用来诊断网络问题
nslookup domain [dns-server]
//如果没有指定dns服务器,就采用系统默认的dns服务器。
查询其他记录
nslookup -qt = type domain [dns-server]
type:
A -->地址记录
AAAA -->地址记录
AFSDB Andrew -->文件系统数据库服务器记录
ATMA -->ATM地址记录
CNAME -->别名记录
HINHO -->硬件配置记录,包括CPU、操作系统信息
ISDN -->域名对应的ISDN号码
MB -->存放指定邮箱的服务器
MG -->邮件组记录
MINFO -->邮件组和邮箱的信息记录
MR -->改名的邮箱记录
MX -->邮件服务器记录
NS --> 名字服务器记录
PTR ->反向记录
RP -->负责人记录
RT -->路由穿透记录
SRV -->TCP服务器信息记录
TXT -->域名对应的文本信息
X25 -->域名对应的X.25地址记录
查询更具体的信息
nslookup -d [其他参数] domain [dns-server]
//只要在查询的时候,加上-d参数,即可查询域名的缓存
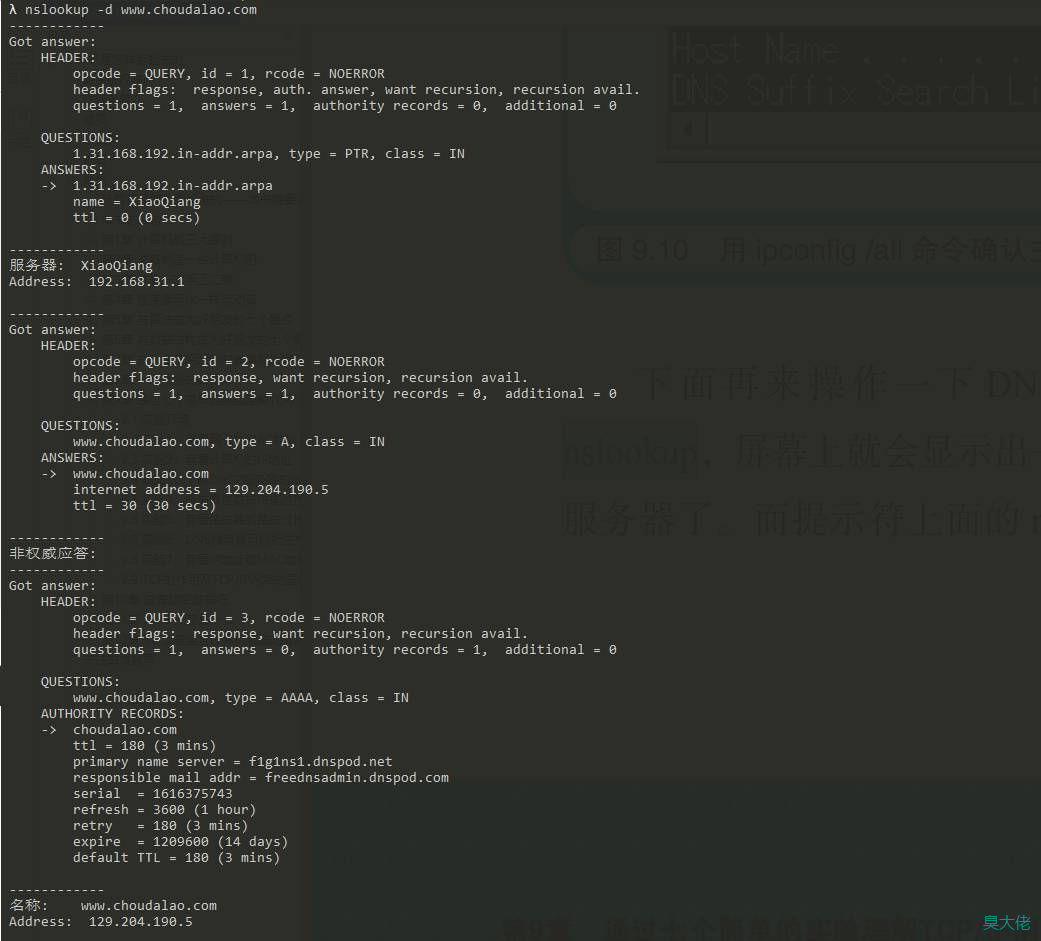
查看 IP 地址和 MAC 地址的对应关系
地址解析协议
在互联网的世界中,到处传输的都是附带了 IP 地址的数据。但是能够标识作为数据最终接收者的网卡的,还是 MAC 地址。于是在计算机中就加入了一种程序,用于实现由 IP 地址到 MAC 地址的转换,这种功能被称作 ARP(Address Resolution Protocol,地址解析协议)。
ARP 的工作方式很有意思。它会对 LAN 中的所有计算机提问:
“有谁的 IP 地址是 210.160.205.80 吗?有的话请把你的 MAC 地址告诉我。”通常把这种同时向所有 LAN 内的计算机发送数据的过程称作“广播”(Broadcast)。通过广播询问,如果有某台计算机回复了 MAC 地址,那么这台计算机的 IP 地址和 MAC 地址的对应关系也就明确了。ARP 的工作流程也是自动进行的,诸位并不会意识到。
如果为了查询 MAC 地址,每回都要进行广播询问,那么查询的效率就会降低。于是 ARP 还提供了缓存的功能,当向各个计算机都询问完一轮之后,就会把得到的 MAC 地址和 IP 地址的对应关系缓存起来(临时保存在内存中)。存起来的这些对应关系信息称作“ARP 缓存表”。只要在命令提示符窗口中执行 arp -a 命令,就可以查看当前 ARP缓存表中的内容。
arp -a

IP 协议
IP 协议用于指定数据发送目的地的 IP 地址以及通过路由器转发数据。
TCP 协议
TCP 协议则用于通过数据发送者和接收者相互回应对方发来的确认信号,可靠地传输数据。
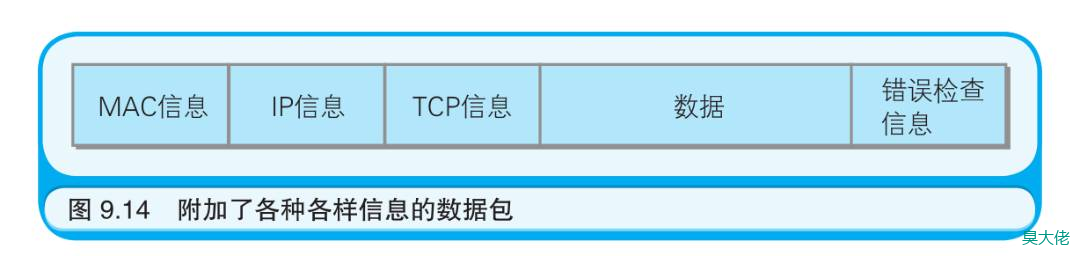
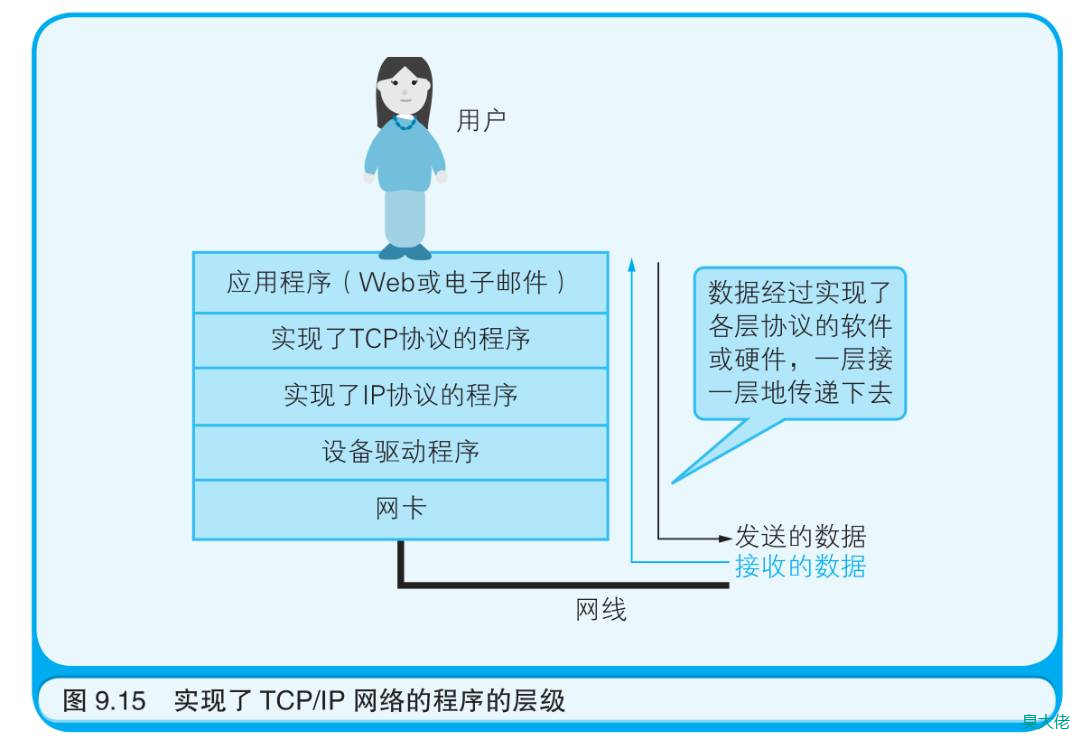
硬件上发送数据的是网卡。在网卡之上是设备驱动程序(用于控制网卡这类硬件的程序),设备驱动程序之上是实现了 IP 协议的程序,IP程序之上则是实现了 TCP 协议的程序,而再往上才是应用程序,比如Web 或电子邮件。这样就构成了一幅在硬件之上堆叠了若干个软件层的示意图。TCP 协议使用被称作“TCP 端口号”的数字识别上层的应用程序。TCP 端口号中有一些是预先定义好的,比如Web 使用 80 端口,电子邮件使用 25 端口(用于发送)和 110 端口(用于接收)。
SE 负责监管计算机系统的构建
SE 是 System Engineer(系统工程师)的缩略语。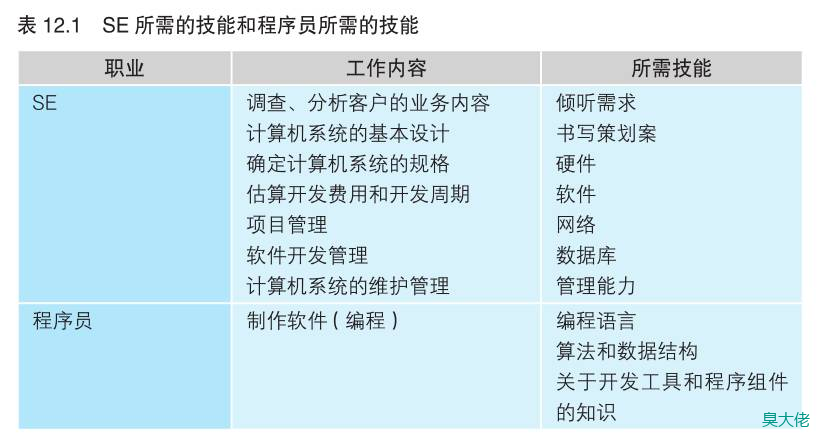
瀑布模型中的 7 个阶段
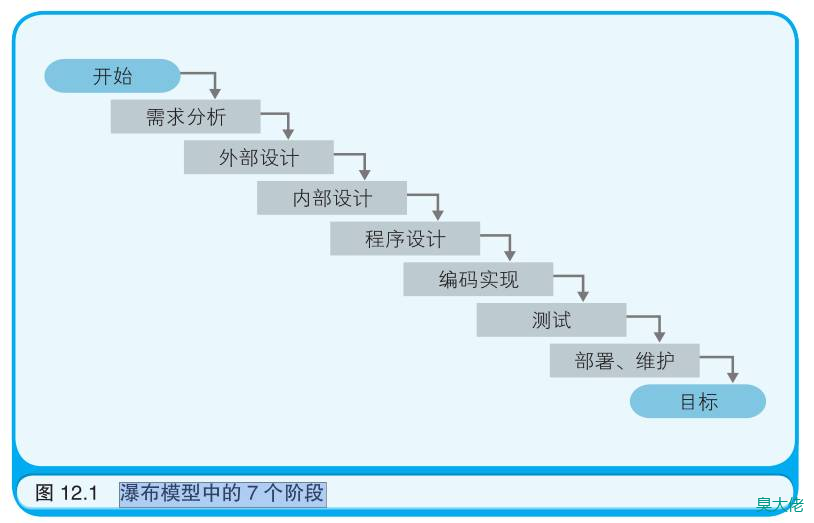
在瀑布模型中,每完成一个阶段,都要书写文档(报告)并进行审核。进行审核时还需要召开会议,在会上由 SE 为开发团队的成员、上司以及客户讲解文档的内容。若审核通过了,就可以从上司或客户那里得到批准,继续进入后续的开发阶段。若审核没有通过,则不能进入后续的阶段。一旦进入了后续的阶段,就不能回退到之前的阶段。为了避免回退到上一阶段,一是要力求完美地完成每一个阶段的作,二是要彻底地执行审核过程,这些就是瀑布模型的特征。这种开发过程之所以被称为“瀑布模型”,是因为开发流程宛如瀑布,一级一级地自上而下流动,永不后退。
各个阶段的工作内容及文档
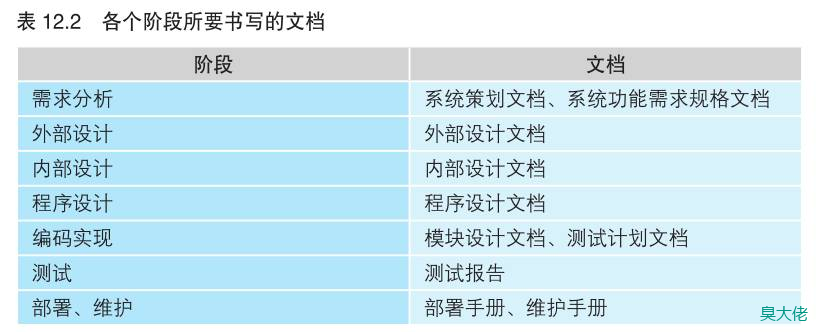
在“需求分析”阶段,SE 倾听将要使用计算机系统的客户的需求,调查、分析目前靠手工作业完成的业务内容。作为本阶段的成果,SE要书写“系统策划文档”或是“系统功能需求规格文档”。
接下来是设计计算机系统,该过程可以分为 3 个阶段。
第一个阶段是“外部设计”,进行与从外部观察计算机系统相关的设计。设计内容包括系统处理的数据、显示在画面上的用户界面以及打印机打印的样式等。第二个阶段是“内部设计”,进行与从内部观察计算机系统相关的设计。内部设计的目的是将外部设计的内容具体化。第三个阶段是“程序设计”,为了用程序将内部设计的内容实现出来而做出的更加详细的设计。作为以上 3 个设计阶段的结果,SE 要分别书写“外部设计文档”“内部设计文档”和“程序设计文档”。
再接下来,就进入了“编码实现”阶段,要进行的工作是编写代码,由程序员根据程序设计文档的内容,把程序输入到计算机中。作为本阶段的文档,SE要书写用于说明程序构造的“模块设计文档”和用于下一阶段的“测试计划文档”。
到了“测试”阶段,测试人员要根据测试计划文档的内容确认程序的功能。在最后编写的“测试报告”中,还必须定量地(用数字)标示出测试结果。如果只记录了一些含糊的测试结果,比如“已测试”或是“没问题”,那么就难以判断系统是否合格了。
如果测试合格了,就会进入“部署、维护”阶段。“部署”指的是将计算机系统引进(安装)到客户的环境中,让客户使用。“维护”指的是定期检查计算机系统是否能正常工作,根据需要进行文件备份或根据应用场景的变化对系统进行部分改造。只要客户还在使用该计算机系统,这个阶段就会一直持续下去。在这一阶段要书写的文档是“部署手册”和“维护手册”。
福利
关注“臭大佬”公众号,回复“计算机是怎样跑起来的”,获取完整版PDF,快来一起学习吧!
本文链接:https://www.choudalao.com/article/247
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。