python 爬取哔哩哔哩的 小视频
python 爬取哔哩哔哩的 小视频
分析
哔哩哔哩的页面请求看了一下,发现小视频模块使用接口获取视频的,
页面地址:https://vc.bilibili.com/p/eden/all#/?tab=%E5%85%A8%E9%83%A8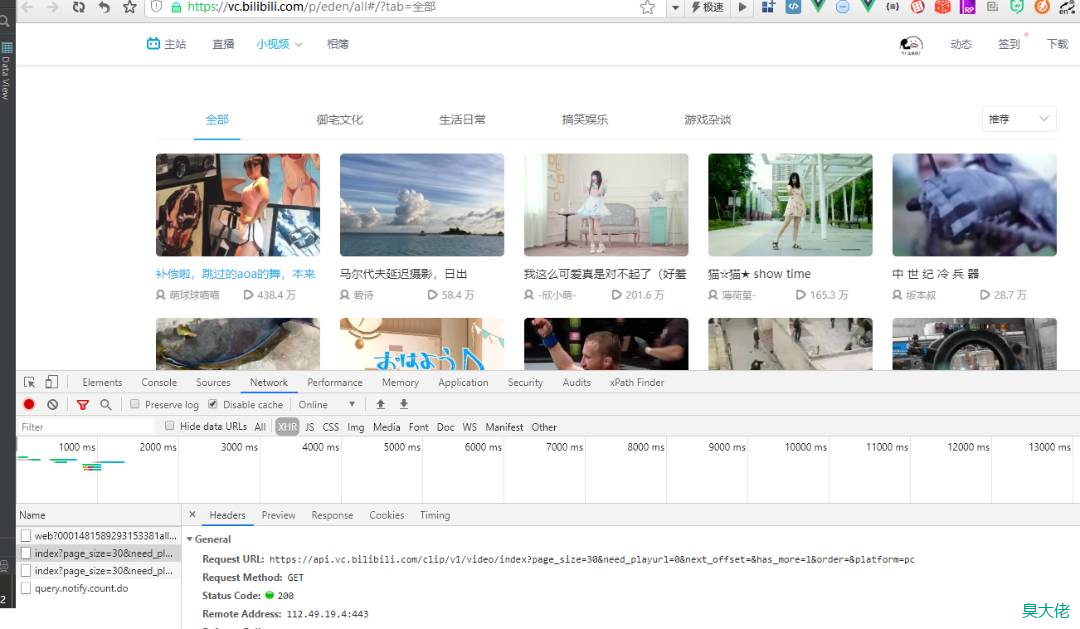
把获取的接口复制到浏览器,进行请求,可以发现video_playurl字段就是视频地址,由此,我们可以根据抓取的内容把视频下载下来。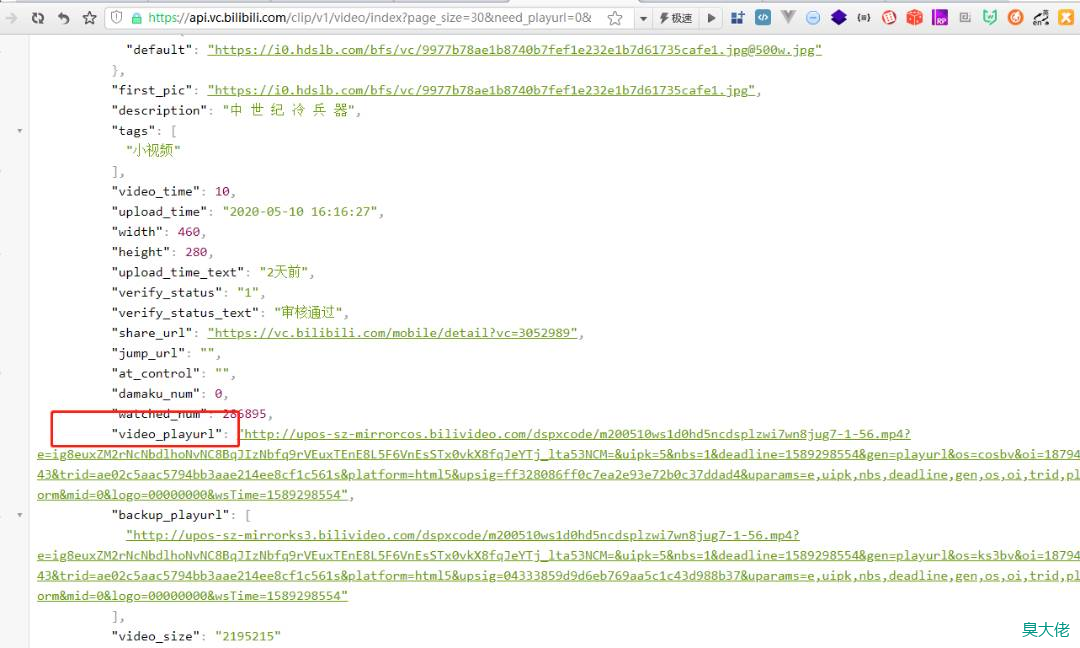
代码
直接上代码:
import requests, re, os
class BSpider(object):
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36'}
self.url = 'https://api.vc.bilibili.com/clip/v1/video/index?page_size=30&need_playurl=0&next_offset={}&has_more=1&order=&platform=pc'
# 解析获取的数据,并从中提取出视频的播放地址和视频的名称
def parse_json(self, json):
items = json['data']['items'] # 视频的数据都放在items中,所以要去遍历items
for item in items:
video_url = item['item']['video_playurl'] # 提取出数据中的播放地址和视频的名称
title = item['item']['description']
self.save_video(video_url, title) # 将视频地址和视频名称传给save_video方法
# 发送请求获取数据
def request_page(self):
count = int(input('请输入你想要爬取的页数,一页30个视频:'))
for i in range(0, count):
response = requests.get(self.url.format(i * 30)).json() # 将返回的json数据转为python中的数据类型
self.parse_json(response) # 将返回的数据传给parse_json方法
# 保存视频到本地
def save_video(self, video_url, title):
res = requests.get(video_url,
headers=self.headers).content # 对视频的播放地址发送请求获取数据,因为视频是二进制数据,所以还需要将返回的数据转为二进制数据然后再去保存,所以这里需要.content
title = re.sub(r'[\,, .。/#!!??@\n\s::————丶*ノヽ*´з]', '', title) # 使用re模块中的sub方法将非法的字符转为空字符串,不然保存视频时出错
filename = './v/'
if not os.path.exists(filename): # 使用os库中的path模块判断filename路径是否存在,不存在则创建
os.makedirs(filename) # 创建多级目录
with open(filename + '{}.mp4'.format(title), 'wb')as f:
f.write(res)
print('已下载{}'.format(title))
def main(self):
self.request_page()
if __name__ == '__main__':
spider = BSpider()
spider.main()
成果
运行代码: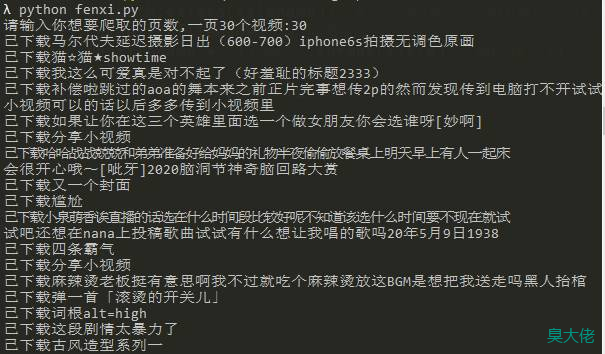
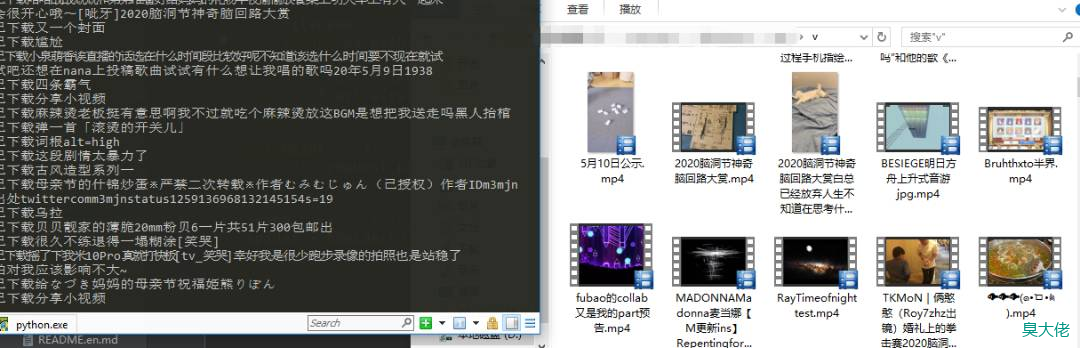
本文链接:https://www.choudalao.com/article/153
转载请注明来源,感谢尊重原创内容。
留言评论
支持表情、回复和点赞。评论需要先登录。