beautifulsoup4爬取臭大佬首页文章
简介
beautifulsoup4爬取臭大佬首页文章
环境
- python3
- win10/ubuntu 16
需要的扩展库
pip install Requests
pip install beautifulsoup4
pip install lxml
目标
抓取臭大佬首页的文章标题
通过 css 选择器获取数据
在目标网页臭大佬首页,单击鼠标右键,选择审
查元素,进入“网络控制台”的“Element”选项卡,在目标元素上,单击鼠标右键,在“copy”栏下,
选择“Copy selector”,我们就可以复制当前元素的 css 选择器。
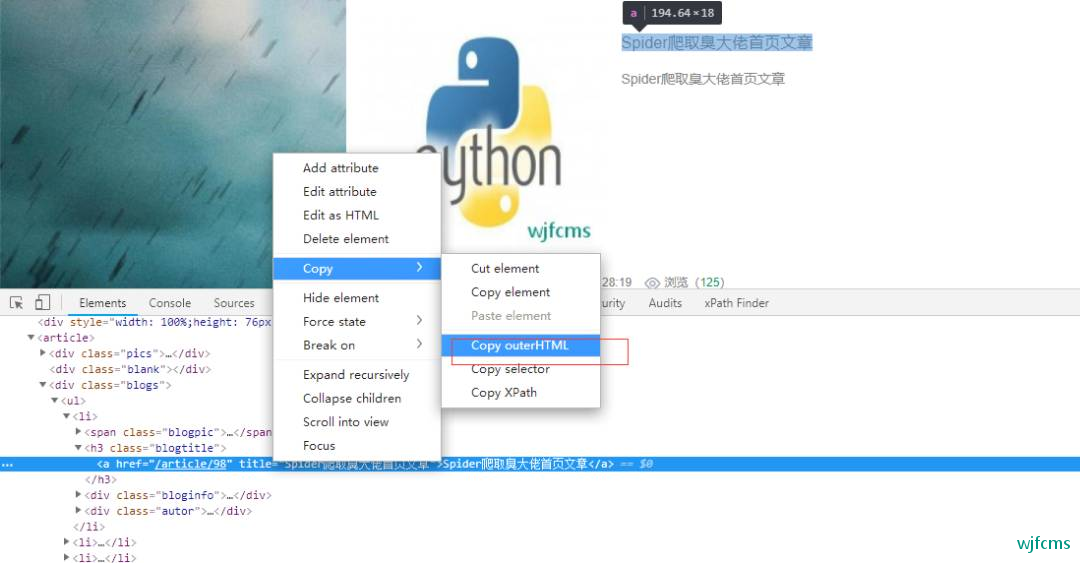
复制出来大概是这样子的
#body_app > article > div.blogs > ul > li:nth-child(1) > h3 > a
稍加修改和调整,就可以作为 BeautifulSoup 能够识别的 CSS 选择器,像这样:
#body_app > article > div.blogs > ul > li > h3 > a
在 BeautifulSoup 中,有两个方法支持 css 选择器:
- .select(css 选择器):返回一个列表,里面包含所有符合 css 选择器条件的元素
- .select_one(css 选择器):返回符合 css 选择器条件的第一个元素
实现爬虫
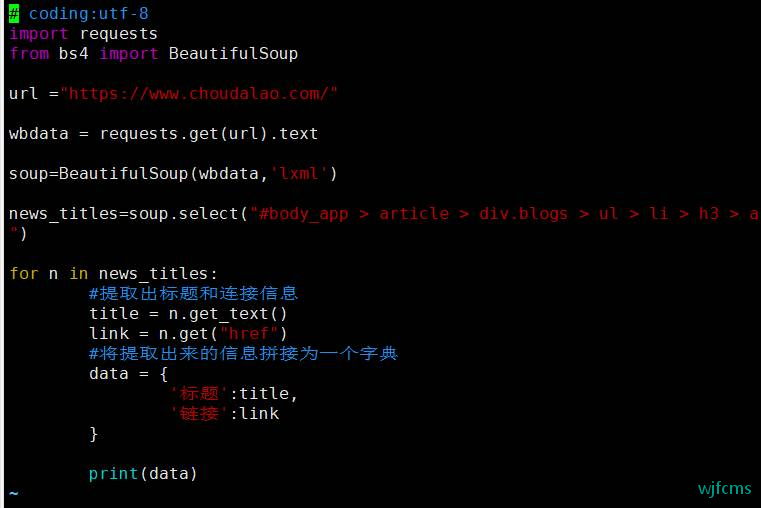
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url ="https://www.choudalao.com/"
wbdata = requests.get(url).text
soup=BeautifulSoup(wbdata,'lxml')
news_titles=soup.select("#body_app > article > div.blogs > ul > li > h3 > a")
for n in news_titles:
#提取出标题和连接信息
title = n.get_text()
link = n.get("href")
#将提取出来的信息拼接为一个字典
data = {
'标题':title,
'链接':link
}
print(data)
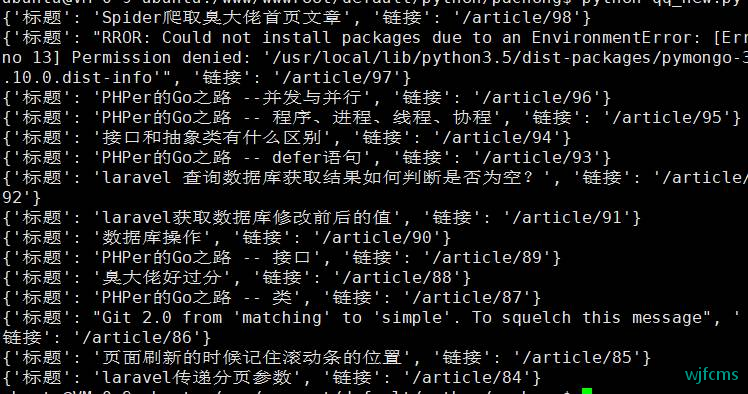
运行
python choudalao.py
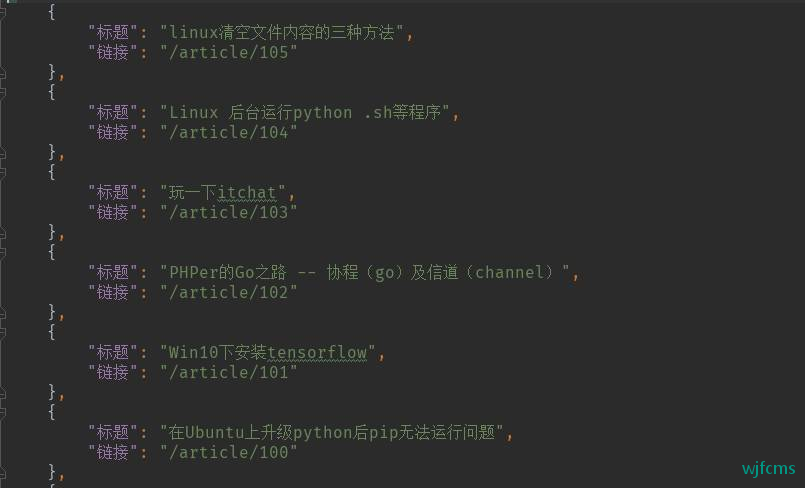
附录
如果对 requests 模块和 BeautifulSoup 模块有更加深的学习欲望,可以查看它们的官方文档:
requests 官方文档(中文): http://docs.python-requests.org/zh_CN/latest/
BeautifulSoup 文档(中文):
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
补充
解决中文乱码问题
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
存储为json
# coding:utf-8
import requests
from bs4 import BeautifulSoup
import json
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
url = "https://www.choudalao.com/"
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata, 'lxml')
news_titles = soup.select("#body_app > article > div.blogs > ul > li > h3 > a")
content = []
for n in news_titles:
# 提取出标题和连接信息
title = n.get_text()
link = n.get("href")
# 将提取出来的信息拼接为一个字典
content.append({'链接': link, '标题': title})
print(title)
# 保存为json
with open('choudalao.json', 'w', encoding='utf-8') as fp:
json.dump(content, fp=fp, ensure_ascii=False, indent=4, sort_keys=True)
广告栏
热度榜
标签云
微信公众号
最新内容会在公众号首发哟☄⊙ω⊙)☄


 微信收款码
微信收款码 支付宝收款码
支付宝收款码